Using AI to Make Promotion Review Preparation More Consistent
Promotion and talent review cycles are among the highest-consequence responsibilities in which a leader participates. They are also easy to under-systematize, allowing differences in packet quality to influence how readily a case can be understood.
The raw material usually arrives in uneven packets: different managers, writing styles, levels of detail, evidence quality, stakeholder feedback, and assumed context. Some packets are crisp and quantitative. Others are sprawling narratives. Some bury the most important evidence on page five. And because these reviews often happen in compressed windows, the people making decisions are forced to move quickly through material that deserves careful attention.
That creates risk because high-stakes people decisions require consistency, and consistency is hard when every packet asks the reviewer to reconstruct the case from scratch.
I believe frontier AI can help here by making preparation more structured, evidence easier to inspect, and uncertainty harder to ignore. The people responsible for the decision retain full accountability.
This was an exploratory preparation aid, not part of a formal talent process and not a system for making decisions. Personnel data should only be handled in environments explicitly approved for that purpose; no workflow benefit outranks privacy, employment policy, or human accountability.
In a promotion process, an employee should not be advantaged because their manager wrote a more polished packet. And they should not be disadvantaged because their manager did not communicate the case as clearly as someone else did.
The review process should be about the strength of the evidence, not the storytelling quality of the packet.
I built an experimental workflow to address this. The goal was to turn raw review material into evidence-backed briefs with a verification layer designed to make each generated claim traceable to source material. The output was a better review surface.
The workflow
The process started with a folder of review packets in mixed formats. Each packet represented one candidate and included some combination of role history, manager narrative, scope changes, accomplishments, stakeholder feedback, growth areas, and recommendation rationale.
From that input, the AI workflow produced:
- A standardized one-page brief for each candidate
- A confidence audit against the original source packets
- A review-readiness view to support discussion order
- An interactive review dashboard for the live meeting
- A notes and decision tracker
- Final shareable artifacts after corrections

Every candidate was reviewed through the same structure, even when the source packets were very different. The workflow was not trying to optimize for the most persuasive packet. It was trying to create a more consistent comparison surface, with the potential to make the preparation fairer.
The AI was not asked to decide who had the strongest case. It was asked to normalize the inputs so the humans in the room could review the cases more consistently.

How each packet was summarized
For each candidate, the AI generated a structured review brief with the same sections.
The first section was basic employee information: current role, proposed role, time in level, manager or sponsor, performance context where available, and promotion history where the source packet supported it.
The second section was a short package snapshot, constrained to two or three sentences designed to answer: what is the case, at a glance?
Then came key accomplishments. The model extracted the strongest examples from the packet and grouped them into a small set of evidence-backed themes. A synthetic example might be:
- Platform modernization across a legacy workflow
- Launch leadership under ambiguous timelines
- Cross-functional operating model improvements
- Mentorship or team-scaling contributions
- Business impact from a newly standardized process
The next section was a scope change table. This was one of the most useful pieces because promotion discussions are often really scope discussions. What changed from the current level to the proposed level? Is the person already operating at that level, or is the packet mostly describing future potential?
After that came stakeholder support. The brief captured who provided feedback, whether they supported the recommendation, and the most specific quote or evidence available. The AI was told to not compress rich feedback into generic phrases like "strong support" if the source contains a more specific reason.
The brief then moved into growth opportunities. Even strong cases should show what the person needs to keep developing.
Then came the section that turned out to be the most valuable: reasons to challenge the recommendation. This section forces the model to act as a "pressure tester." It pushes on the case: Is the scope expansion demonstrated or just aspirational? Are stakeholder quotes specific or generic? This changes the AI from a cheerleader into a partner that prepares me for the hard questions a panel will ask.
Each brief ended with four practical decision-support sections:
- Key questions for the panel
- Risk if not approved
- Impact if the person leaves
- Replacement difficulty
Those sections helped move the discussion from "is this person good?" to "what decision are we making, what evidence supports it, and what questions still need a human answer?"
Checking accuracy against the source
The most important part of the AI workflow was the verification layer.
After the briefs were generated, I ran a confidence audit against the original packets. The instructions to the AI were explicit: do not verify the generated summary against itself. Go back to the source material.
For every data point, the audit classified the claim as one of four categories:
- Verified: the claim matches the source material
- Cross-referenced: the claim is not in this candidate's packet, but is supported by another available source
- Inferred: the claim is plausible, but not actually present in the source
- Error: the claim conflicts with the source

That classification created a much clearer review surface. A sentence that reads confidently in a summary can have very different meanings depending on whether it is verified, inferred, or wrong.
The audit was designed to catch specific failure modes that show up when using AI on personnel material:
- Invented profile links or external references
- Guessed stakeholder titles
- Generic paraphrases replacing specific evidence
- Manager summaries presented as direct stakeholder feedback
- Scope details bleeding from one candidate into another
Asking a model to "double-check" its own work is not enough. If the model only reviews the summary it already wrote, it can confirm its own mistakes.
The verification pass has to force source-grounding.
The rule became: if the source does not support it, mark it unknown. Do not fill the gap with a plausible guess. Once the initial audit surfaced structural omissions, I returned to the available material and ran a fresh source-grounding pass.
Using an LLM as an evidence judge, not a talent judge
This is where the "LLM as judge" pattern became useful.
In this workflow, one pass generated the structured brief. A separate judging pass evaluated whether the generated claims were actually supported by the source material.
In people decisions, AI should not be the decision-maker. It should not own the recommendation, weigh the tradeoffs, or replace the accountability of the leaders in the room.
But AI can be useful as an evidence auditor, especially when the task is repetitive, detail-heavy, and vulnerable to inconsistency.
The judging layer was not asked to decide who should be promoted. It answered a narrower and more auditable question: can this claim be backed up?
The judging layer also made uncertainty visible. Instead of burying uncertainty inside polished prose, the workflow surfaced it. Missing title? Mark it as missing. Feedback behind a link? Note that limitation. Scope table synthesized from narrative instead of explicitly stated? Flag it.
That made the final human discussion better because I could distinguish between evidence, interpretation, and open questions.
The dashboard
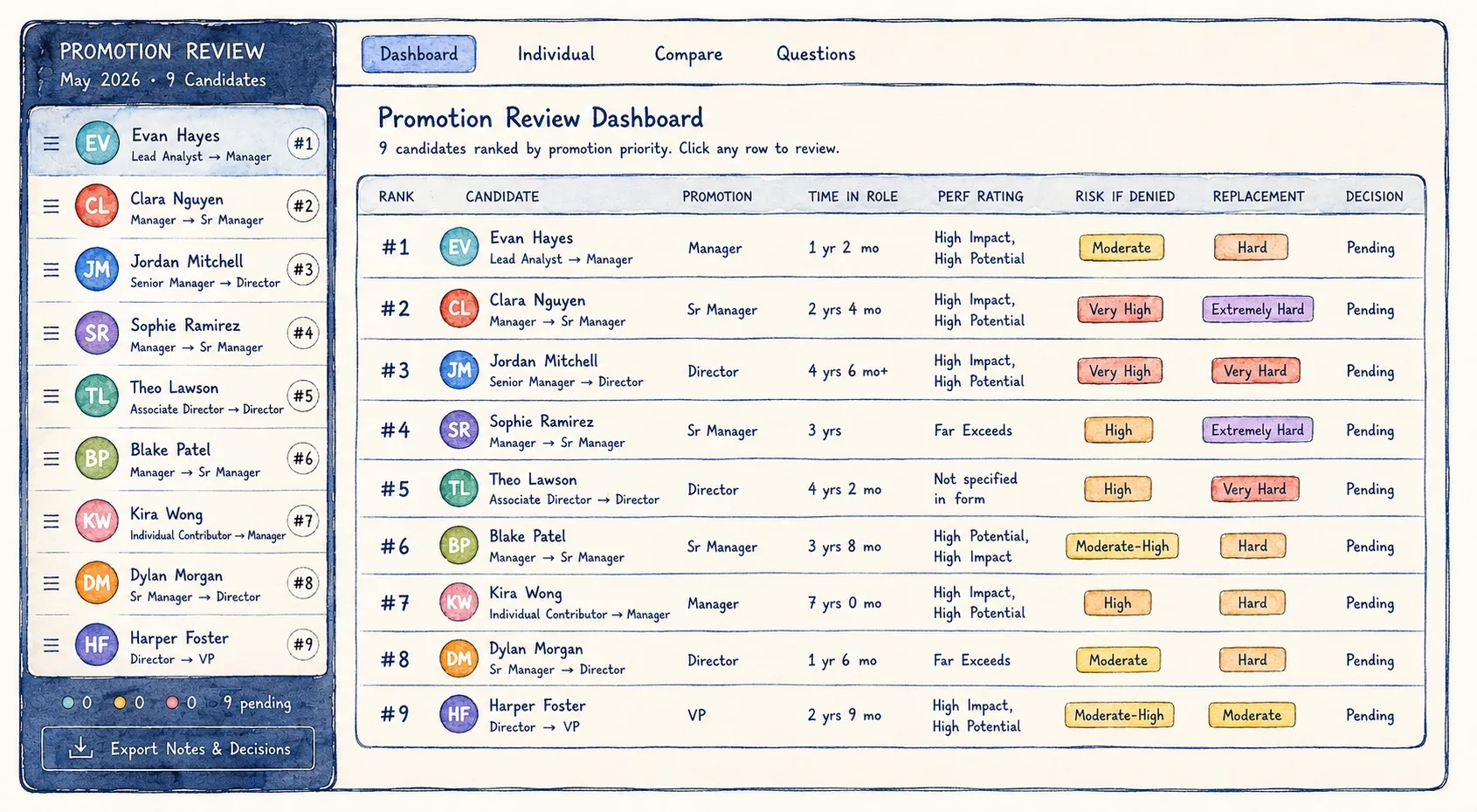
The final step was turning the briefs into an interactive dashboard for the live review meeting.
The dashboard had a candidate sidebar for quick navigation, a summary table, filters for which sections to show, an individual candidate view, side-by-side comparison for two or three candidates, a questions-only view, approve/defer/deny tracking, and a notes field for capturing discussion.
Instead of jumping between long documents, I could compare candidates through the same structure. If the conversation moved to risk, every candidate's risk section was available. If the group needed to focus only on open questions, there was a questions view. If a decision changed during discussion, the tracker updated the tally.
The dashboard did not replace judgment. It reduced the amount of cognitive overhead required to exercise judgment well.
What changed
The bigger benefit was consistency. Every candidate got the same sections, every case got a challenge section, every summary went through a source-grounding audit, and every uncertainty had somewhere to go. I did not measure whether the workflow produced fairer outcomes. The narrower claim is that a more consistent comparison surface can reduce the influence of packet polish and make gaps in the evidence easier for reviewers to see.
Frontier AI tools are well-suited to this kind of work because they can absorb messy inputs, produce structured outputs, and then help critique those outputs. But they only become useful when the workflow is designed with controls:
- Standardize the summary format
- Require source-grounded claims
- Add an explicit verification pass
- Use an LLM as a judge for evidence quality
- Preserve human accountability for the decision
I don’t want AI ever making promotion decisions. I want AI helping leaders prepare so rigorously that our human judgment is as fair and consistent as possible.
For product leaders, the near-term opportunity is to automate preparation while preserving accountability, standardize evidence without standardizing the outcome, and use speed to make the process more careful rather than more casual.
The best use of AI in leadership work is creating the conditions for better, more consistent human judgment.
Author’s note: I used this workflow as part of my own preparation for participating in a review panel. It was not used as part of the formal promotion review process, and it was not used to make or determine any promotion decision.
For a tool or workflow like this to become part of an official talent process, it would need the appropriate level of due diligence, governance, privacy review, HR review, legal review, and organizational alignment. That was not the case here. This was a personal preparation exercise to help me engage with the material more consistently and thoughtfully.
My hope is that the lessons from experiments like this can inform carefully governed tools that help leaders and employees make important people processes more consistent and evidence-based without delegating the decision.